|
I am a PhD student at MIT advised by the wonderful Armando Solar-Lezama and a founding research lead at Math, Inc (we're hiring!).
My research focuses on improving the capabilities of AI systems on tasks like programming and mathematics.
I completed my bachelor's and Master's degrees at MIT, advised by Armando and Jacob Andreas. I have done internships at Meta FAIR, Amazon ARG, NVIDIA, Jane Street, and pony.ai. My research is generously funded by the NSF GRFP.
Google Scholar / Twitter / SoundCloud / YouTube / WeChat |

|
{kind=link}
|
[Feb 2026] ProofOptimizer, a recipe for training language models to simplify Lean proofs, is accepted to ICLR 2026! [Oct 2025] IneqMath is accepted to NeurIPS 2025 as a Spotlight! [Jun 2025] Our paper on challenges and future directions in AI for Software Engineering is accepted to ICML 2025! [Apr 2025] Zhaoyu Li and I are hosting a social on AI for Mathematics and Theorem Proving at ICLR 2025! [Mar 2025] I started an internship at Meta in Menlo Park working on AI and Lean with Aram Markosyan. |
|
|

|
Alex Gu, Bartosz Piotrowski, Fabian Gloeckle, Kaiyu Yang, Aram H. Markosyan ICLR, 2026 ProofOptimizer combines a symbolic linter, a fine-tuned 7B language model specialized for proof simplification, and an iterative inference algorithm that progressively shortens proofs. It can reduce proof length by over 87% on MiniF2F and 57% on PutnamBench, and even halve the size of recent IMO proofs. |

|
Jiayi Sheng*, Luna Lyu*, Jikai Jin, Tony Xia, Alex Gu, James Zou*, Pan Lu* NeurIPS 2025 (Spotlight) In IneqMath, we dive deep into the ability of LLMs to solve Olympiad-level inequality proofs. We reveal a critical gap: LLMs are often good at finding answers, but struggle with rigorous, sound proofs. |
|
Alex Gu, Naman Jain, Wen-Ding Li, Manish Shetty, Yijia Shao, Ziyang Li, Diyi Yang, Kevin Ellis, Koushik Sen, Armando Solar-Lezama ICML, 2025 In this paper, we first discuss challenges in today's AI systems for software engineering. Then, we propose a set of promising future research directions to address these challenges. |
|
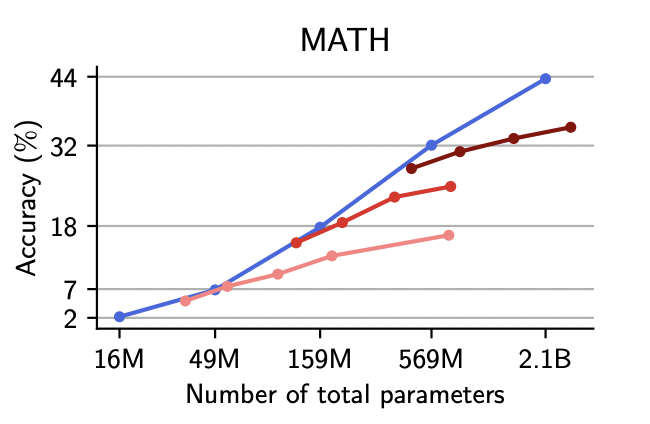
Samy Jelassi, Clara Mohri, David Brandfonbrener, Alex Gu, Nikhil Vyas, Nikhil Anand, David Alvarez-Melis, Yuanzhi Li, Sham M. Kakade, Eran Malach ICLR, 2025 In this paper, we compare MoEs and dense transformers. Our main finding is that as the number of experts increases at constant active parameter count, memorization performance increases while reasoning capabilities saturate. |
|
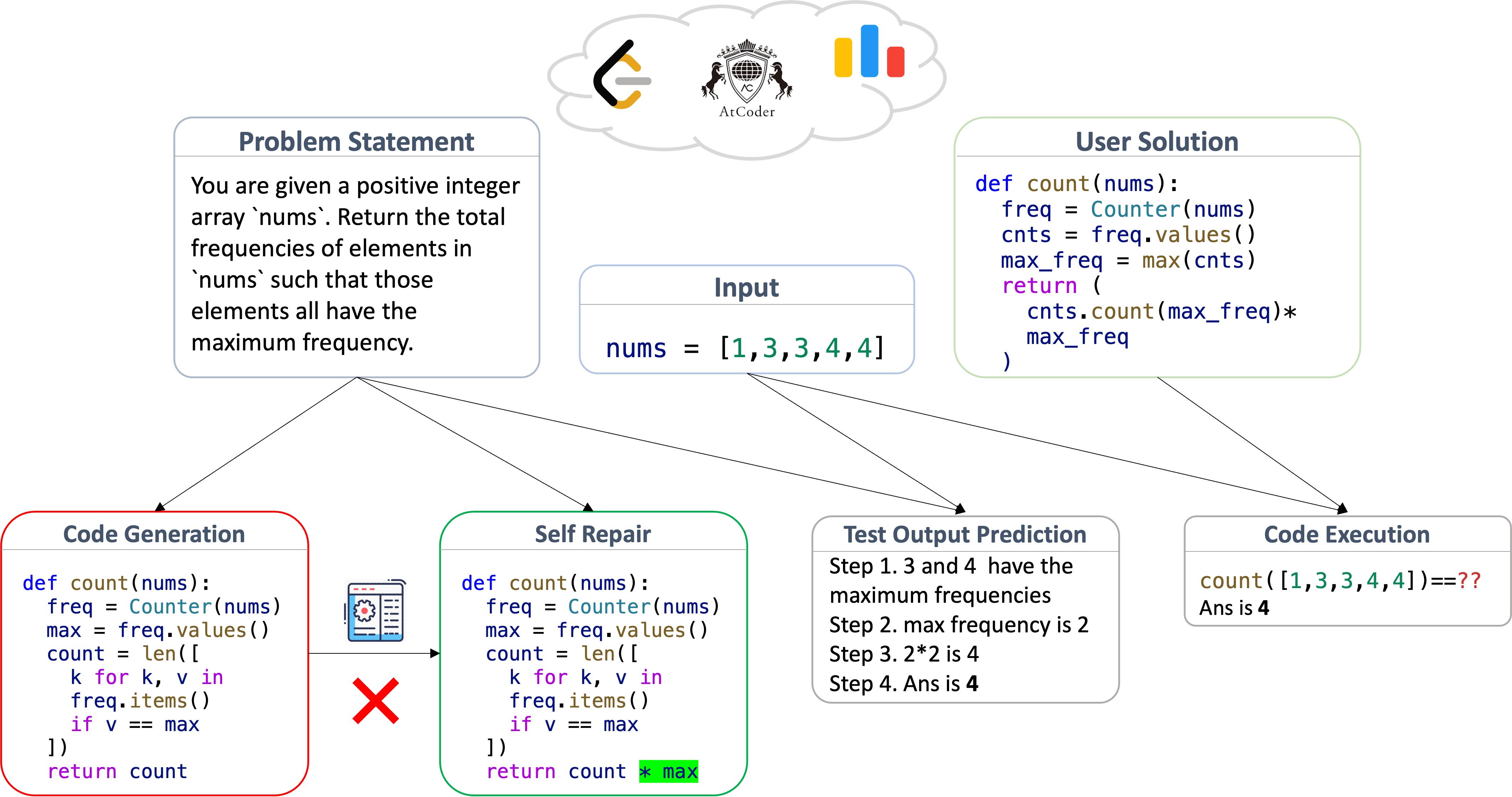
Naman Jain, King Han, Alex Gu*, Wen-Ding Li*, Fanjia Yan*, Tianjun Zhang*, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica ICLR, 2025 LiveCodeBench is a holistic and contamination-free benchmark for code LMs. It consists of 4 tasks: code generation, self-repair, code execution, and test output prediction. We update the benchmark periodically with new high-quality problems from platforms like LeetCode, AtCoder, and Codeforces. |

|
Alex Gu, Wen-Ding Li*, Naman Jain*, Theo X. Olausson*, Celine Lee*, Koushik Sen, Armando Solar-Lezama ACL Findings, 2024 In The Counterfeit Conundrum, we analyze the ability of open code language models to understand their counterfeit samples. These are samples that 1) have a high enough log-probability to be generated at a moderate temperature, 2) are incorrect, but 3) pass weak correctness checks. We find that open code LMs 1) think counterfeits are correct, 2) execute them as if they were correct, and 3) can't repair them without feedback. |

|
Anton Lozhkov, ..., Alex Gu, ..., Leandro von Werra*, Harm de Vries* We train new models with 3B, 7B, and 15B on Software Heritage source code including 619 programming languages and high-quality data sources like GitHub pull requests, Kaggle notebooks, and code documentation. Our models outperform most similarly sized models on a variety of benchmarks. |

|
Alex Gu, Baptiste Rozière, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, Sida I. Wang ICML, 2024; DMLR & DPFM Workshops @ ICLR 2024 CRUXEval is a benchmark of 800 Python functions and input-output pairs designed to test the ability of code LMs on code reasoning, understanding, and execution. We find that despite being trained on 100G of Python code and 1T of code data, models like Code Llama fail over half the time at simple execution prediction and code reasoning! |
|
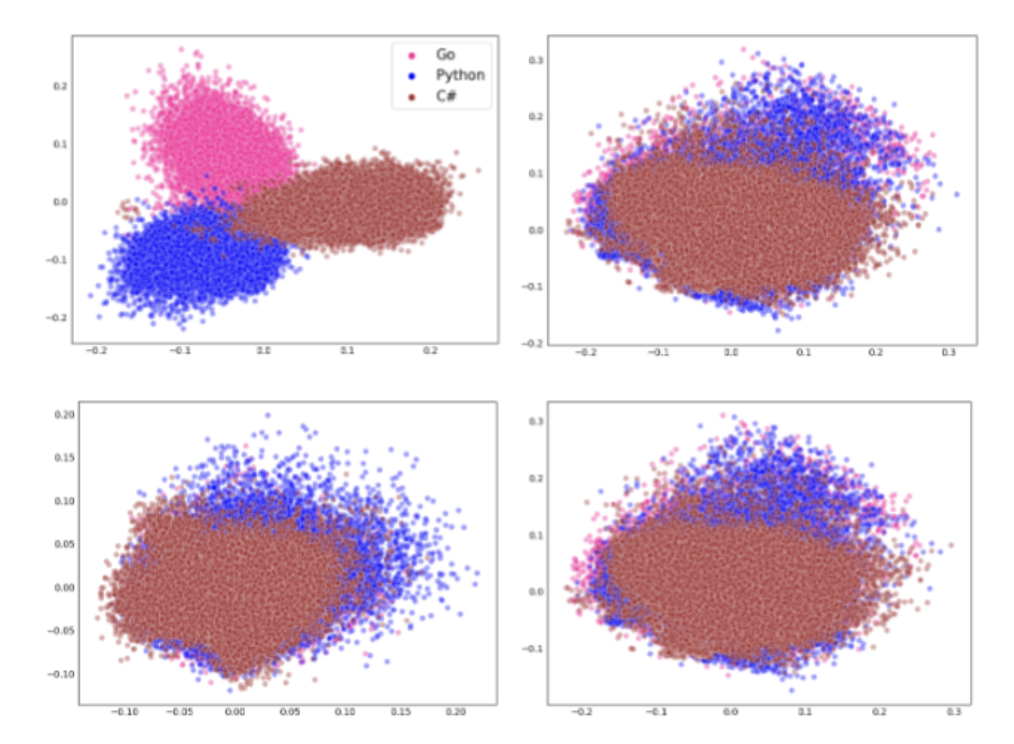
Saiteja Utpala, Alex Gu, Pin Yu Chen NAACL, 2024 We apply a method used in multilingual NLP on code, showing that vector embeddings for code can be decomposed into syntax-like and semantic-like components. We show that when removing the syntax-like component, language identification becomes expectedly difficult, and Text2Code and Code2Code retrieval performance improves. |
|
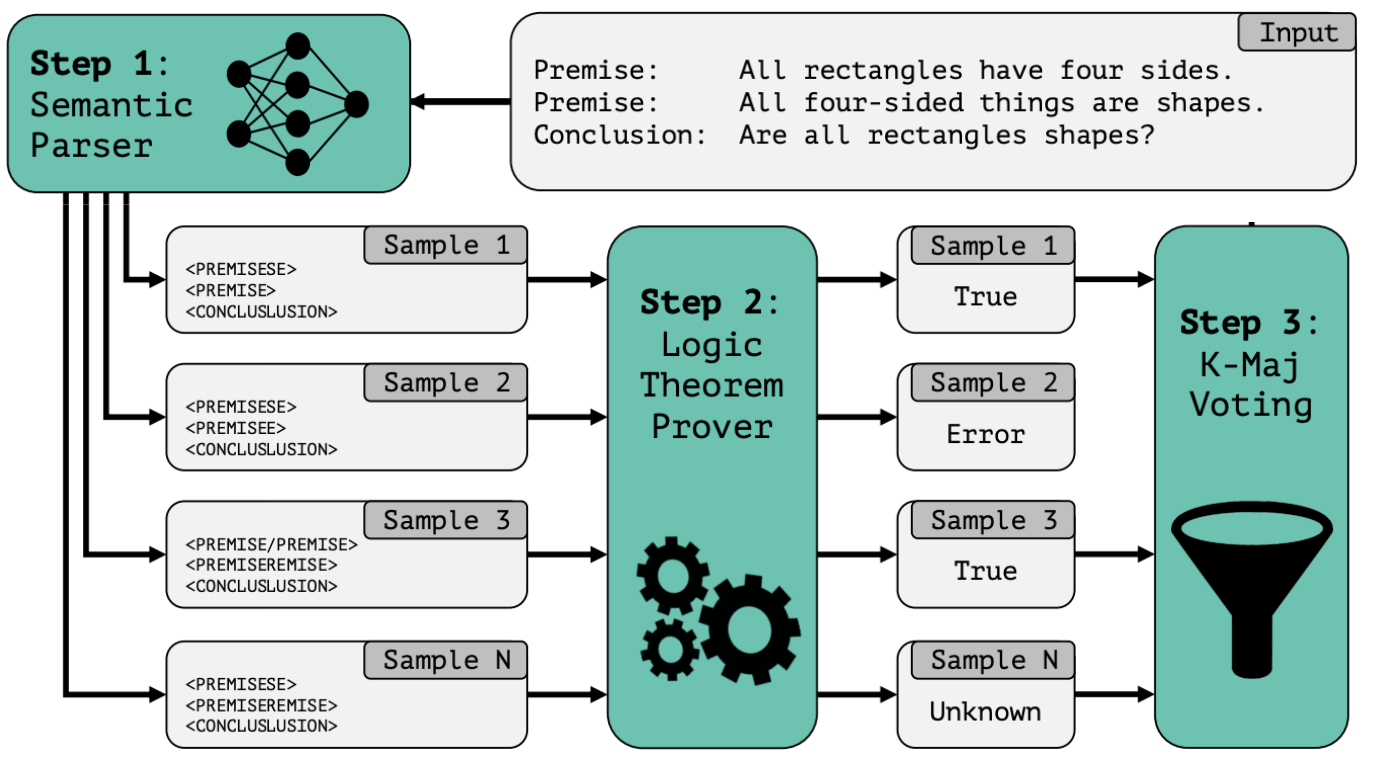
Alex Gu*, Theo X. Olausson*, Benjamin Lipkin*, Cedegao E. Zhang*, Armando Solar-Lezama, Joshua B. Tenenbaum, Roger Levy EMNLP 2023, Outstanding Paper Award in Commonsense and Reasoning We propose, LINC, a neurosymbolic approach to logical reasoning from natural language where the LLM acts as an autoformalizer to first-order logic and a logic theorem prover makes a deduction. We also qualitatively compare LINC to chain of thought, showing they make different mistakes and thus are complimentary. |
|
|
Kaiyu Yang, Aidan Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, Anima Anandkumar NeurIPS Datasets and Benchmarks Track 2023, Oral presentation We release LeanDojo: an open-source playground consisting of toolkits, benchmarks, and models for LLMs to prove formal theorems in the Lean proof assistant. LeanDojo contains 1) tools for data extraction and interaction with Lean, 2) fine-grained annotations of where lemmas are used and defined, 3) a new benchmark of 97K human-written theorems from mathlib, and 4) a retrieval-augmented theorem prover using retrieval for relevant premise selection. |
|
|
Raymond Li, ..., Alex Gu, ..., Leandro von Werra*, Harm de Vries* TMLR, 2023 StarCoder and StarCoderBase are 15.5B parameter models with 8K context length, infilling capabilities, and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. |
|
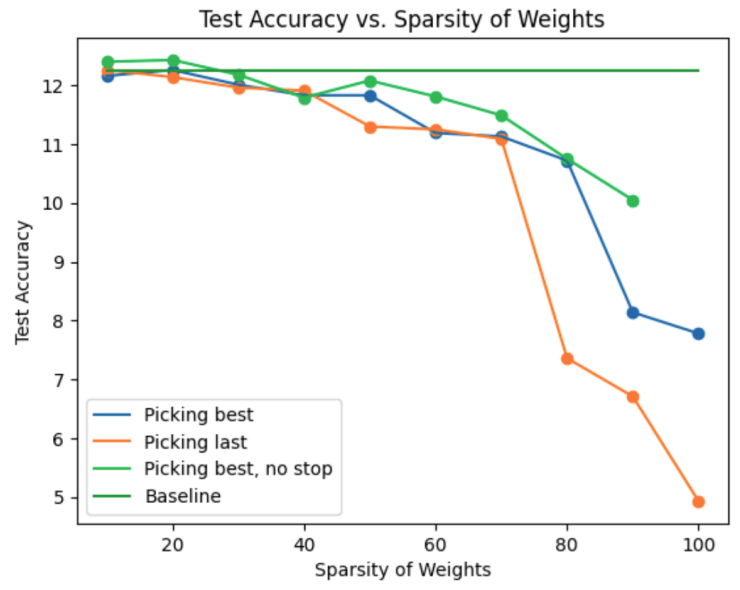
Alex Gu, Ria Sonecha, Saaketh Vedantam, Bharat Runwal, Diganta Misra Workshop on Sparsity in Neural Networks, ICLR 2023 We do some very preliminary experiments on pruning the encoder piece of CodeBERT. Preprint coming soon, but if you're interested in this topic, please reach out! |

|
Alex Gu, Songtao Lu, Parikshit Ram, Lily Weng ICLR 2023 [Video from ICML 2021 workshop] We extend standard single-objective bilevel optimization to a min-max multi-objective framework that aims to minimize the worst-case loss of all tasks. Our main result is theoretical: we introduce a new algorithm (MORBiT) for our framework and show a convergence result. We also highlight applications in representation learning and hyperparameter optimization. |
|
|
Loubna Ben Allal*, Raymond Li*, Denis Kocetkov*, ..., Alex Gu, ..., Leandro von Werra* Deep Learning for Code Workshop, ICLR 2023 [Best Paper] The BigCode project is an open-scientific collaboration working on the responsible open-source development of large language models for code. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack, and our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling. |
|
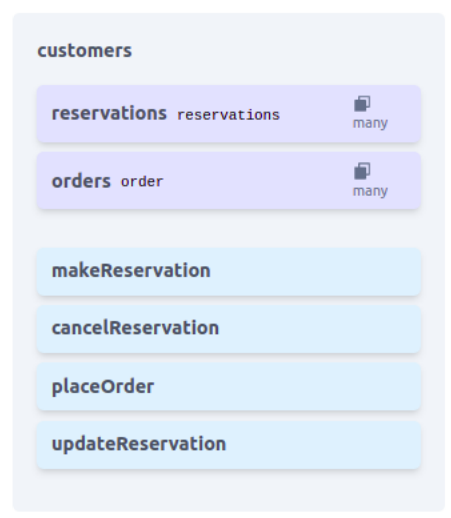
Alex Gu, Tamara Mitrovska, Daniela Velez, Jacob Andreas, Armando Solar-Lezama Deep Learning for Code Workshop, ICLR 2023 ObSynth leverages domain knowledge embedded in GPT-3 to help users design object models from high level natural language prompts. We synthesize object names, field names, field types, method names, and relationships between objects. Also, we conduct a user study to highlight how users may interact with ObSynth to design a restaurant management application. |

|
Satyapriya Krishna*, Tessa Han*, Alex Gu, Javin Pombra, Shahin Jabbari, Steven Wu, Himabindu Lakkaraju Workshop on Trust and Reliance in AI-Human Teams, CHI 2022 We introduce the disagreement problem in explainable machine learning, showing that commonly used algorithms including LIME, SHAP, and SmoothGrad often disagree in practice. We also conduct a user study highlighting that practitioners do not have good ways of resolving these disagreements in their day to day. |
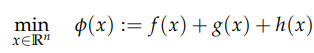
|
Alp Yurtsever*, Alex Gu*, Suvrit Sra NeurIPS 2021 [Video] Standard three operator splitting minimizes the sum of three convex functions f(x) + g(x) + h(x), where f is smooth and the prox operators of g and h are computable. We focus on three settings: (i) f is nonsmooth, (ii) we only have noisy gradients and subgradients of f, (iii) an adaptive setting where smoothness properties of f are unknown.
|

|
Alex Gu, Tsui-Wei Weng, Pin-Yu Chen, Sijia Liu, Luca Daniel Workshop on Machine Learning for Autonomous Driving, NeurIPS 2020 [Video] Our algorithm, CORGI, computes certified bounds on an interpretability algorithm known as CAM (Class Activation Mapping), showing that within the certified radius, the top-K pixels of the CAM map do not change. |
If you find my work interesting, I am happy to give a talks to anyone who is interested!
|
RestBot - Online Interactive Breaks Revive Positive Thinking and Behavior during COVID-19
The intention of this research project is to explore alternative methodologies available to people who are struggling with quarantine and isolation, providing them with an opportunity to resuscitate positive thinking and behavior. The result of the study proved that direct online social engagement can be an alternative way to resuscitate positive thinking and behavior for everyone under strenuous circumstances, such as during COVID. |
|
Estimating the Lipschitz Constant of Neural Networks
An (unsuccessful) attempt to estimate the Lipschitz constant of neural networks via running optimization techniques on the gradient norm. |
|
Dex Synthesizer
A synthesizer for toy programs in the Dex Programming Language |
|
Exploring Founded Semantics for Static Analysis
A toy exploration of how founded semantics can help static analysis. |
|
Neural Network on FPGA
Implementation of a feedforward neural network on FPGA in Verilog |
|
CUTHBERT: Comprehensive aUTo-arrangement algoritHm for BEats n’ RhyThms
CUTHBERT, a music generator that uses Markov chain models to gain an intuition for music, is a software tool designed to remove knowledge barriers for new musicians and provide inspiration to experienced musicians that just need an idea to start writing. |
|
Comparing Sketching Algorithms for Nearest Neighbor Search
A comparison of six different sketching algorithms for nearest neighbor search (run time/accuracy) on MNIST, GloVe, and SIFT. |
|
Ray Tracer
A ray-tracer written in OCaml based on The Ray Tracer Challenge by Jamis Buck. |
Previously, I studied classical piano under Yukiko Sekino and Chun-Chi An. Here are some recordings of concerts I have given in the past:
|
Recital, Spring 2023 [Program Notes]
Ludwig van Beethoven, Sonata Op. 57, No. 23 "Appassionata" (1806)
|
|
Recital, Spring 2022 [Program Notes]
Alexander Scriabin, Piano Sonata No. 2 in G-sharp minor (1897)
|
|
Performance with MIT Symphony Orchestra, Spring 2022
Rachmaninoff Piano Concerto No. 2 in C minor, Op. 18
|
|
Recital, Spring 2021 [Program Notes]
Claude Debussy, Images, Book 1 (1905)
|
Once in a while, I also enjoy creating my own music.
|
A sentimental piece that I co-created with my friend Boom once for New Year's. |
|
A remix of Parry Gripp's hit song, It's Raining Tacos, which often kept me sane in my undergraduate days. |
|
A remix of another one of my guilty pleasure songs, 学猫叫 (Learn to Meow). |
|
A surreal, jolly, but nostalgic piece reflecting on the past. |
|
Thanks to Jon Barron for the awesome website template. Last updated on February 20, 2026. |